
It's 2026 and the next evolution of Identity Governance & Administration (IGA) is hitting the market. Agentic IGA is no longer an idea but is reality. Since the recent StackBob.ai announcement, many people have asked how Agentic IGA differs from existing automation like Robotic Process Automation (RPA / BOTS), and how this is going to reshape the IGA market.
This article explains what Agentic IGA is, what it is not, and why it is going to accelerate IGA deployments as an extension of current IGA programs while also reshaping the future of identity governance.
Agentic IGA Definition
In short:
Agentic IGA is an identity governance model in which autonomous agents execute, reconcile, and adapt identity lifecycle actions directly within target applications, dynamically selecting the most effective interaction mechanism at runtime, while preserving existing IGA policy, controls, and audit models.
This definition is comprehensive, but to understand how transformative this model is, it helps to revisit the history of IGA.
From Humble Beginnings to Core Technology
To explain what Agentic IGA is, I need to take a step back and go over the history of IGA and the major milestones over the years. I’ve been fortunate to have deployed in pretty much all these different stages and can attest to how we have improved and finally have what we have been looking for.
The diagram below outlines the history of IGA, along with the precursor technology.
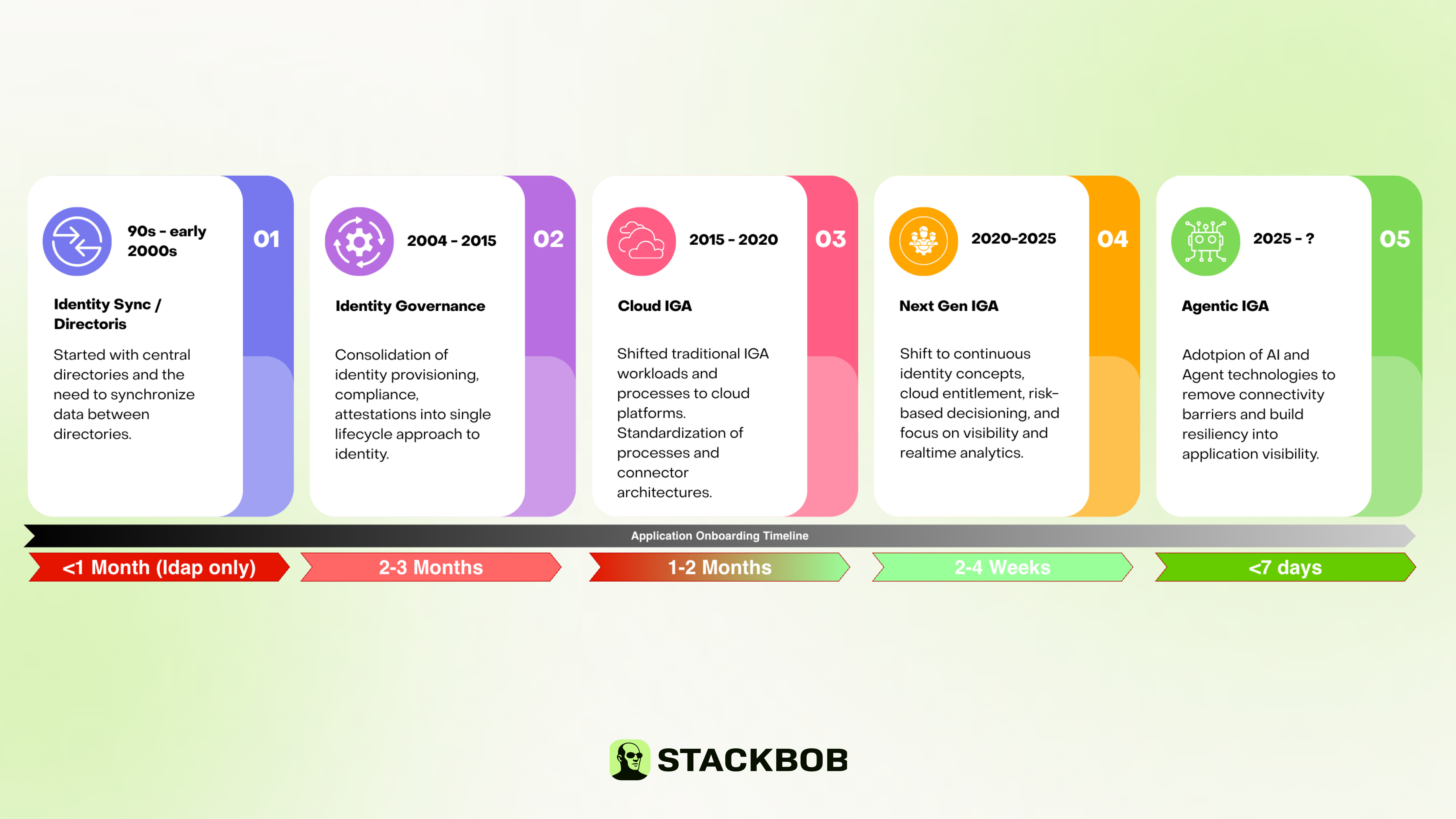
Starting in the early 90s until the early 2000s, applications were on-premises and largely controlled by central directories (LDAP). We had local databases also but pretty much everything was accessible from a central location or via WAN connections. Directory sync technologies (I did MIIS) allowed for synchronizing these directories across disparate directory servers, so you had a single central ‘account’ sync’d to different directories. At the same time, you had things like Novel and IBM starting to develop identity provisioning products across directories and database / applications.
But, in 2004, we had the Sarbanes-Oxley (SOX) regulations come about and we instantly had the need to not only sync but manage permissions and identity lifecycles as part of our financial controls. This brought about Identity Governance (originally coined by SailPoint) which brought in the concepts of provisioning, certification and attestation, and joiner/mover/leaver. This is where the market really took off and you saw everyone coalesce on the IGA concept and capabilities.
With the introduction of the cloud, organizations and vendors all started shifting to cloud delivered applications and services. For IGA vendors, this meant they could deliver their products in uniform, controlled environments and manage delivery. But this also started limiting (or fixing in a lot of cases) IGA capabilities so we had standardized flows and capabilities. In the on-premises world, customers could customize often causing support and performance issues. The cloud standardized a lot of this into predefined flows and capabilities that could be delivered at scale to everyone at an economical price point. This really accelerated IGA to more people that traditionally couldn’t afford such platforms and capabilities.
While the Cloud IGA accelerated adoption, we still had support issues with SaaS and the vast number of applications that organizations use. NextGen IGA vendors took this on to centralize application connectors into more of a shopping cart list of applications. This allowed for fast onboarding and governance of applications. Additionally, they started focusing on the data models and vast amounts of data that IGA platforms have available. This helped onboard more applications, faster, and started focusing on the processes around IGA (e.g. SoD, Certifications, JML, etc.) and offloaded ungoverned applications to things like ServiceNow so it could centralize the process and visibility of identity onboarding.
Enter 2025 and Agentic IGA being introduced to the market. Now to this point, IGA as a technology has really matured in its capabilities to govern identities and data it has visibility to, but is still reliant on connectors, API support, etc. Additionally, where we do have connectors and standards like SCIM, IGA data models don’t always map to the limits of SCIM (users and groups only). This is where Agentic IGA is focused. Using AI models and agents, we have the capability to use THE BEST combination of connectors to a target application at a point and time. This may be API, SCIM, agent, or a combination of all the above. Agentic IGA is taking the capabilities of existing IGA and accelerating the onboarding of target applications and its available technologies, not necessarily what the IGA platform supports. This is a much different model than previous IGA milestones in that we now can focus on connecting the target application, not how we connect it.
Why Agentic IGA Matters
Above, I went over the IGA timeline and major market shifts for the technology. One thing I did not go over is the target applications and how they are connected to IGA. To highlight this challenge, I’m adding an overlay on the milestones highlighting the connector development timelines.

With IGA, we are heavily reliant on two, arguably three things to be able to govern an application.
- Target application must have a user / entitlement management API.
- We must have a framework to connect to that API to pull in user and entitlement data.
- ARGUABLE: skilled resources to be able to develop scripted connectors and internal IGA functionality.
In the beginning stages of the IGA maturity, this was heavily reliant on LDAP, database, or in a lot of cases, writing custom Identity Connector Framework (ICF) connectors (see https://github.com/OpenIdentityPlatform/OpenICF) to map IGA capabilities to target application supported APIs. As everything started moving to the cloud around 2009/2010, LDAP and databases largely started having problems and we became reliant on scripting connectors (most vendors have them centered on Groovy, JavaScript, etc.). This model progressed and matured over time, but we still have roughly a 2–4-week development cycle to onboard an application (assuming it has an API, those without APIs don’t really have an option until later).
Now, you may say that is not a lot of time to onboard an application. Which, I agree, that is BETTER than when it took me 2 months but let’s also look at the average number of applications organizations are using. In 2025, the average small to medium organization uses 300+ applications (they know of). If the average organization has 30-40% of existing applications onboarded (we’ll leave out to what level), that leaves ~210-180 applications not onboarded to IGA. At 2-4 weeks per application, that would be ~400 weeks of effort to onboard everything (assuming this number doesn’t grow which it always does). The diagram below highlights what this upwards trend looks like along with where Agentic IGA is going to address this problem.
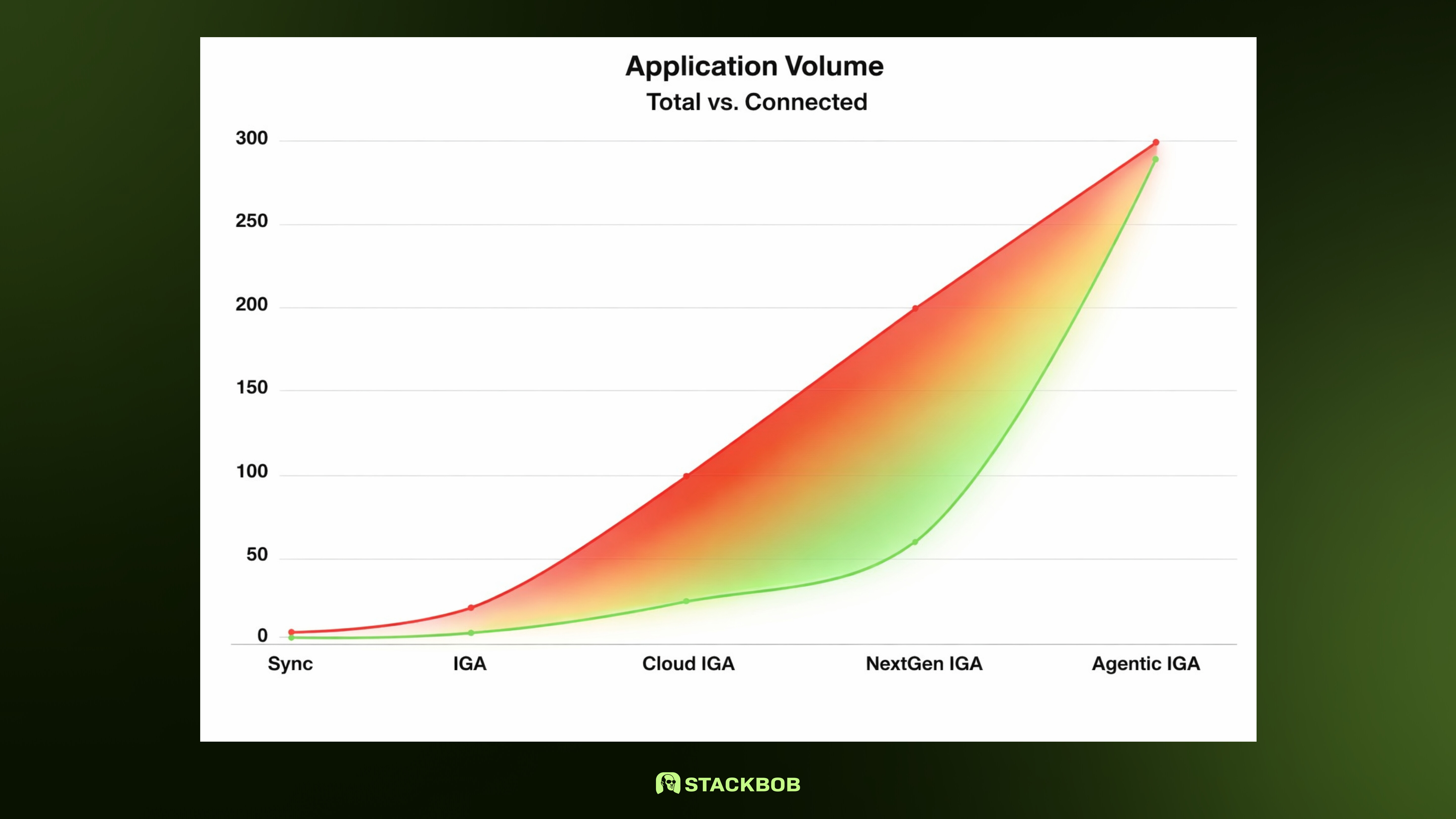
Taking the Agentic IGA approach, we’re seeing it takes <48 hours to train the model on new application functionality then a few hours to days to connect the application to IGA tooling. Given the average sprint of 2 weeks, teams could be adding multiple applications per sprint once it has been approved, acquired, and being released to business units to use. Additionally, this requires less development resources per target application since is largely handled by internal IGA functionality, less on scripting and development.
How is this different from existing techniques?
To address the connector and API gaps, there are a few predominant options that we’ve been using the last few years that Agentic IGA will make much easier and more resilient. The two options most people use:
- Service management / flatfile: This has been my go-to the last few years. Idea here, the IGA platform holds the policy and determines what someone should have access to then sends a ticket to ITSM platforms for the fulfillment. In place of an automated connector, use automatic ticket creation and manual fulfillment. To reconcile access, organizations do ‘regular’ imports from target systems to reconcile and identify gaps / rogue access.
- RPA / Bots: I’ve seen the growth of bot technology the last few years to take requests (direct or via ITSM tickets) and use browser automation to fulfill requests. This has taken some of the load of helpdesk and application owners but still requires flatfiles or other means to reconcile existing access (unless you can train bot to run a report / export and put in a share which is not always the case).
The diagram below outlines what this looks like in existing IGA deployments.
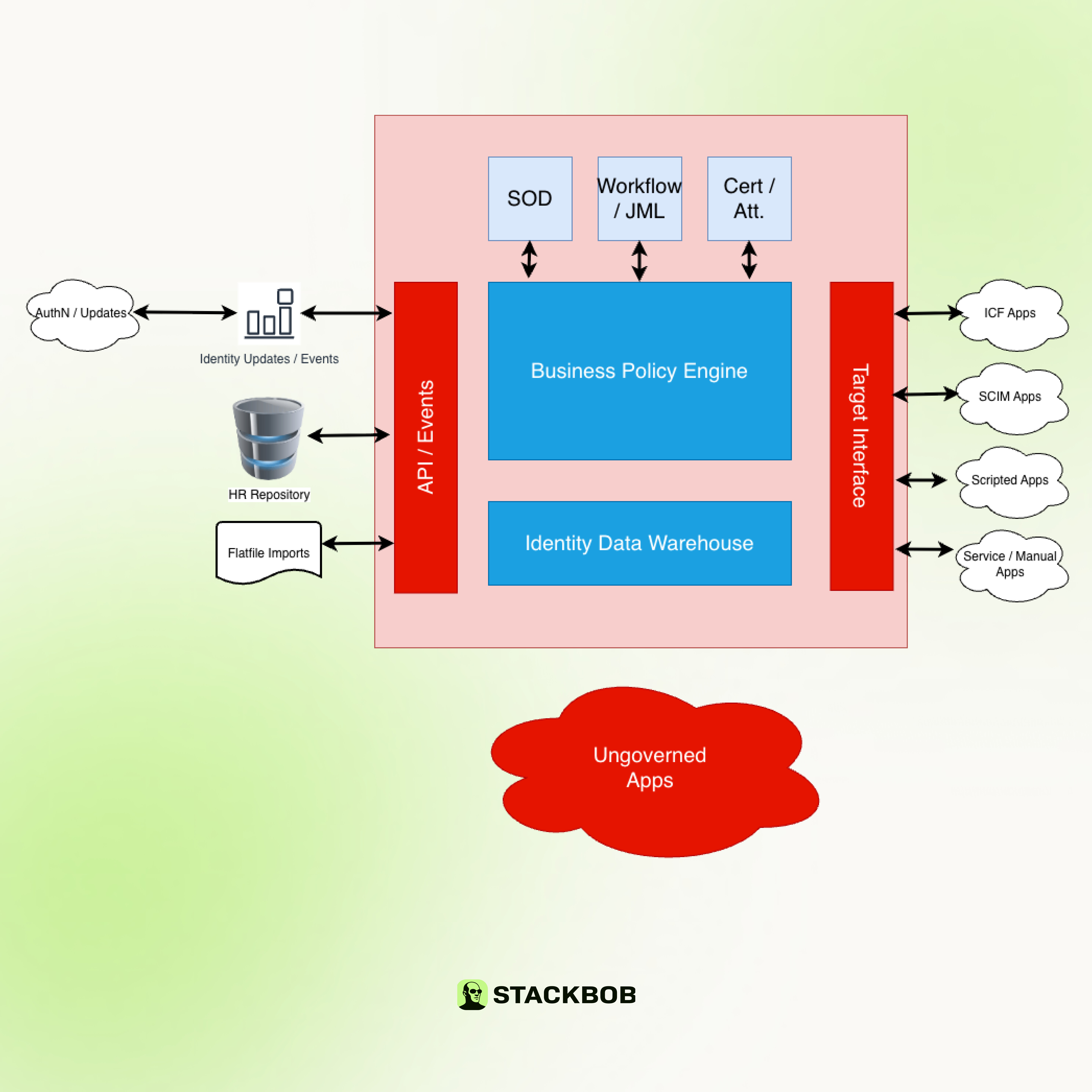
Both these were viable options at the time and work in most cases. But time has shown, these are not that resilient. We have teams ‘closing’ requests and not fulfilling them, problems getting teams to provide exports regularly, changes to applications break bots, etc. Additionally, training bots required additional teams to build and maintain scripts.
Agentic IGA is meant to work alongside existing technologies and address the current gaps and accelerate onboarding. The diagram below shows the functional shift in this technique.
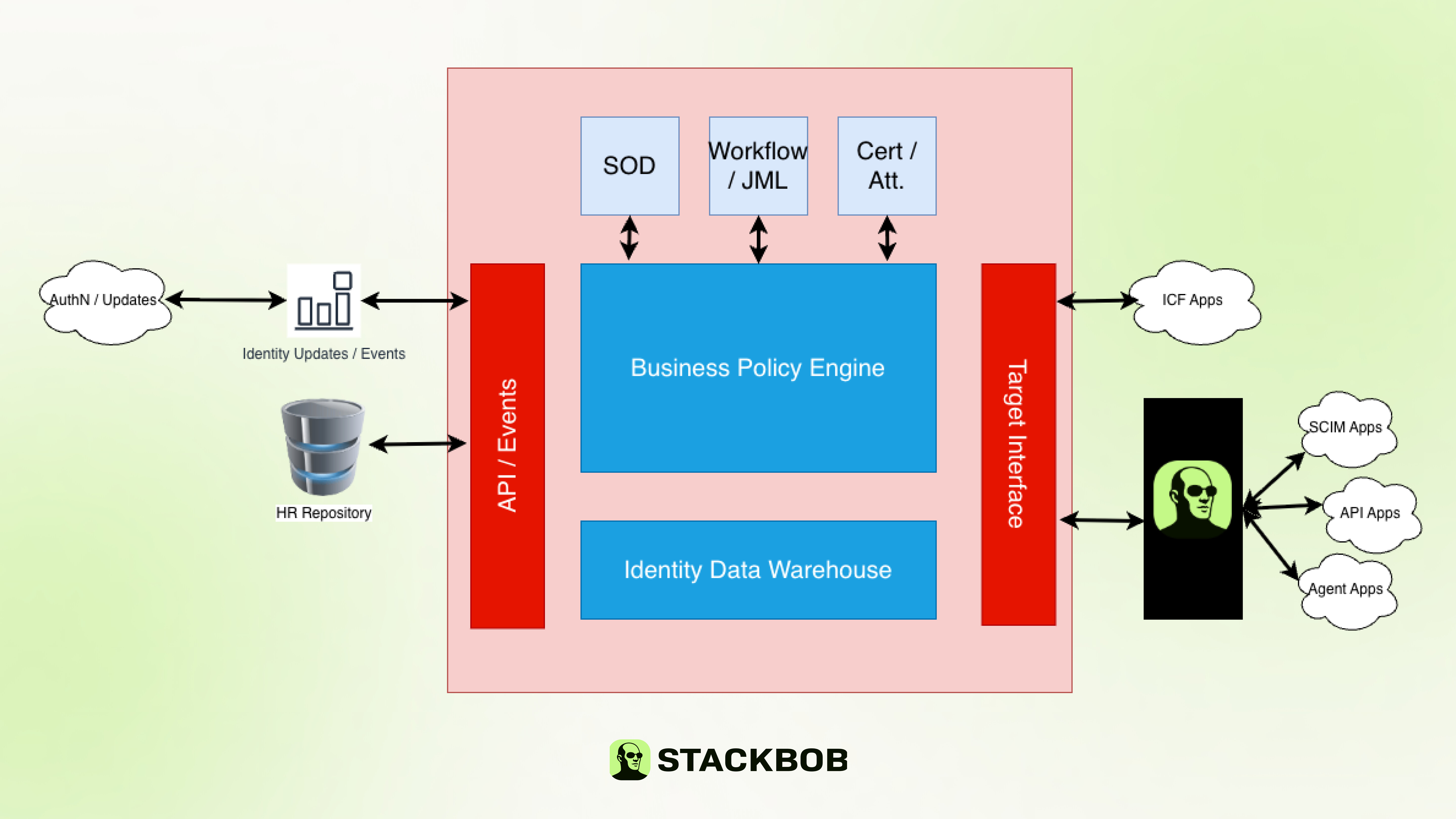
Notice the difference un architecture here. Existing IGA data and policy flows stay in place. Agentic IGA addresses the target application identity data. The power of this is the model can determine the appropriate connection(s) to a target application given the requested change. There may be a combination of SCIM / agent to achieve a single request rather than SCIM / manual that is done today (based on target application support). This also removes the API and flatfile requirements since models are trained to reconcile data and provide standard API responses.
Are there gaps?
In our testing with design clients and customers, we’ve been able to get upwards of 80-90% target application coverage. Why not 100%, well there are always going to be blockers for some. Legacy applications, connection problems (for security reasons, e.g. older systems not connected to networks, etc.) are there for a reason and are next to impossible to address.
Final thoughts
Agentic IGA is the next evolution of years or working towards the continuous identity security mantra. IGA has always had the working order to automate the identity lifecycles so we can identify and reduce risk, reduce access times, and enable users to get the access they need, when needed. We’ve been largely blocked to date based on application supports, connectors, and resource limitations. With this new technology, we can start planning application onboarding based on sprint schedules, not long implementation programs and plans.